DeepSeek just admitted something most wouldn’t say out loud
On December 1st, 2025, DeepSeek released DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. Both models are fully open-source under the MIT license, with a detailed technical report published alongside. The benchmarks are impressive—approaching state-of-the-art on multiple fronts. But buried in the paper is a sentence that cuts through the hype:
The performance gap between closed-source and open-source models appears to be widening.
This is DeepSeek—one of China’s leading AI labs—acknowledging a trend that many suspected but few stated so plainly: the gap between the open-source camp (largely China-based) and the closed-source frontier labs (OpenAI, Anthropic, Google) isn’t shrinking. It’s growing.
The paper doesn’t hide the reason: Fewer Total Training FLOPs. Limited by total compute, DeepSeek-V3.2 still lags behind closed-source leaders in World Knowledge—the breadth of factual information a model can draw upon.
Since 2022, U.S. export controls have restricted China’s access to cutting-edge AI chips. What we’re witnessing isn’t just a technical divergence—it’s the emergence of two parallel AI ecosystems shaped by fundamentally different constraints.
Silicon Valley’s bet: scale until something happens
The path chosen by OpenAI, Anthropic, and Google is a classic combination of brute-force engineering and capital firepower.
The technical foundation is the Scaling Hypothesis: the belief that continuously stacking model parameters, data volume, compute investment, and training paradigms will yield performance improvements following a power law—eventually producing emergent capabilities we can’t yet predict.
On the capital side, this has become an enormous bet. Hundreds of billions in CapEx deployed upfront, marginal costs be damned, racing to see who reaches the next era first.
If this path actually leads to something approaching AGI, the first movers will lock in a triple monopoly: compute infrastructure, foundation models, and platform ecosystems. It’s a Winner-Takes-All logic—every step up in model capability attracts more developers and cash flow, making it nearly impossible for resource-efficient latecomers to close the gap.
China’s bet: efficiency under hard constraints
The “pragmatic restraint” visible in China’s AI narrative is largely a forced choice, not a philosophical preference.
Geopolitics and chip export controls create hard constraints. There’s simply no way to stack GPU clusters without limit the way Silicon Valley can. But this constraint has, perhaps accidentally, installed a kind of “anti-bubble guardrail” on the ecosystem—forcing players from day one to focus on architectural efficiency and real revenue-generating applications in manufacturing, healthcare, and government services.
DeepSeek-V3.2’s three technical breakthroughs are products of exactly this pressure—squeezing maximum intelligence out of every available FLOP.
DSA (DeepSeek Sparse Attention): To handle the compute cost of long-context scenarios, they introduced sparse attention that compresses the main attention computation from near-quadratic complexity allowing more information to be processed within limited memory.
Post-training compute > 10% of pre-training: This is an aggressive budget allocation by any standard. DeepSeek poured over 10% of their pre-training compute into post-training, heavily investing in reinforcement learning and tool-use capabilities to compensate for pre-training compute limitations.
Large-scale agentic task synthesis pipeline: By building 1,800+ distinct environments and 85,000+ complex prompts, they pushed the model’s “doing work” capabilities to approach closed-source leaders—even if raw world knowledge still lags.
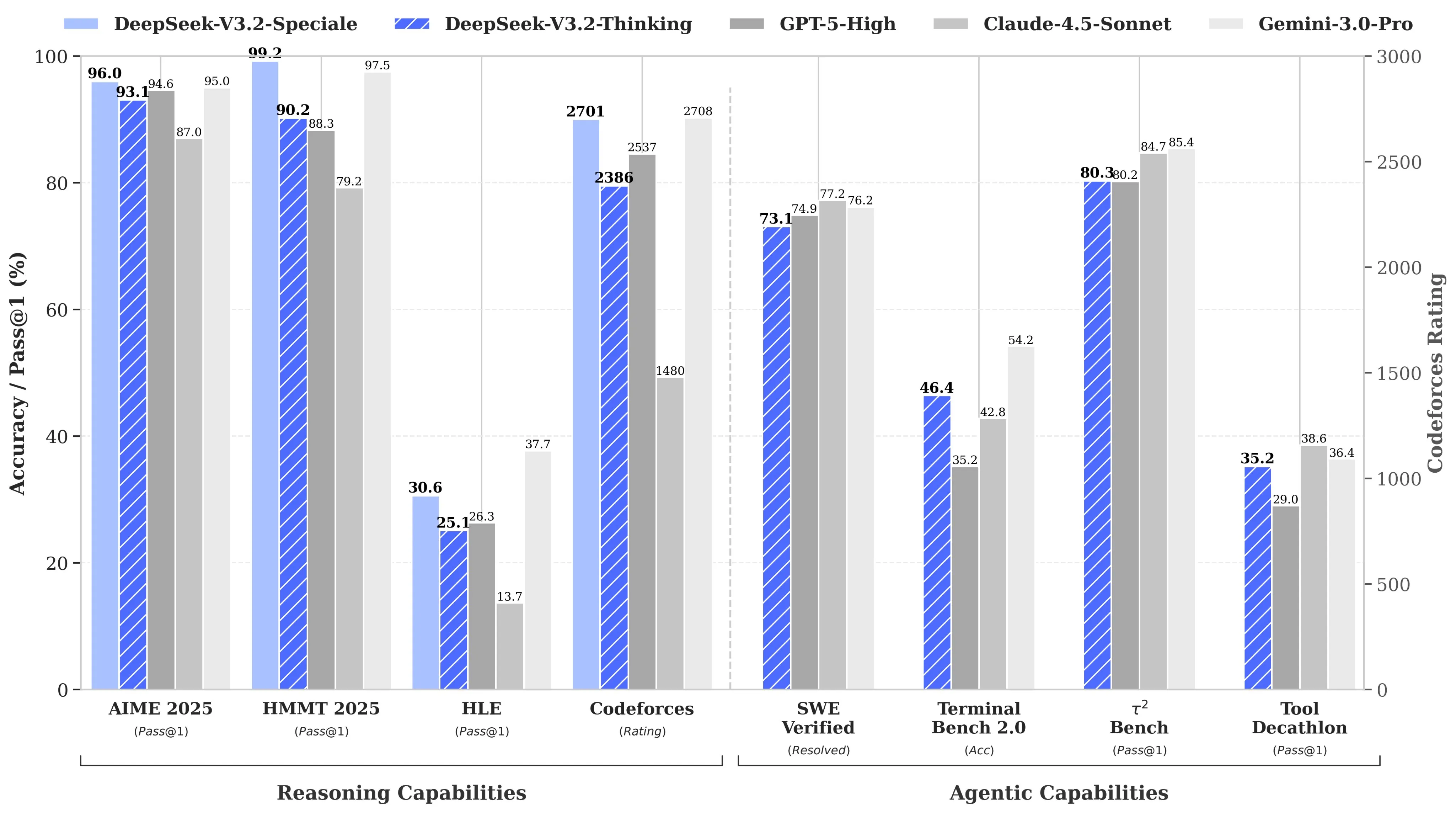
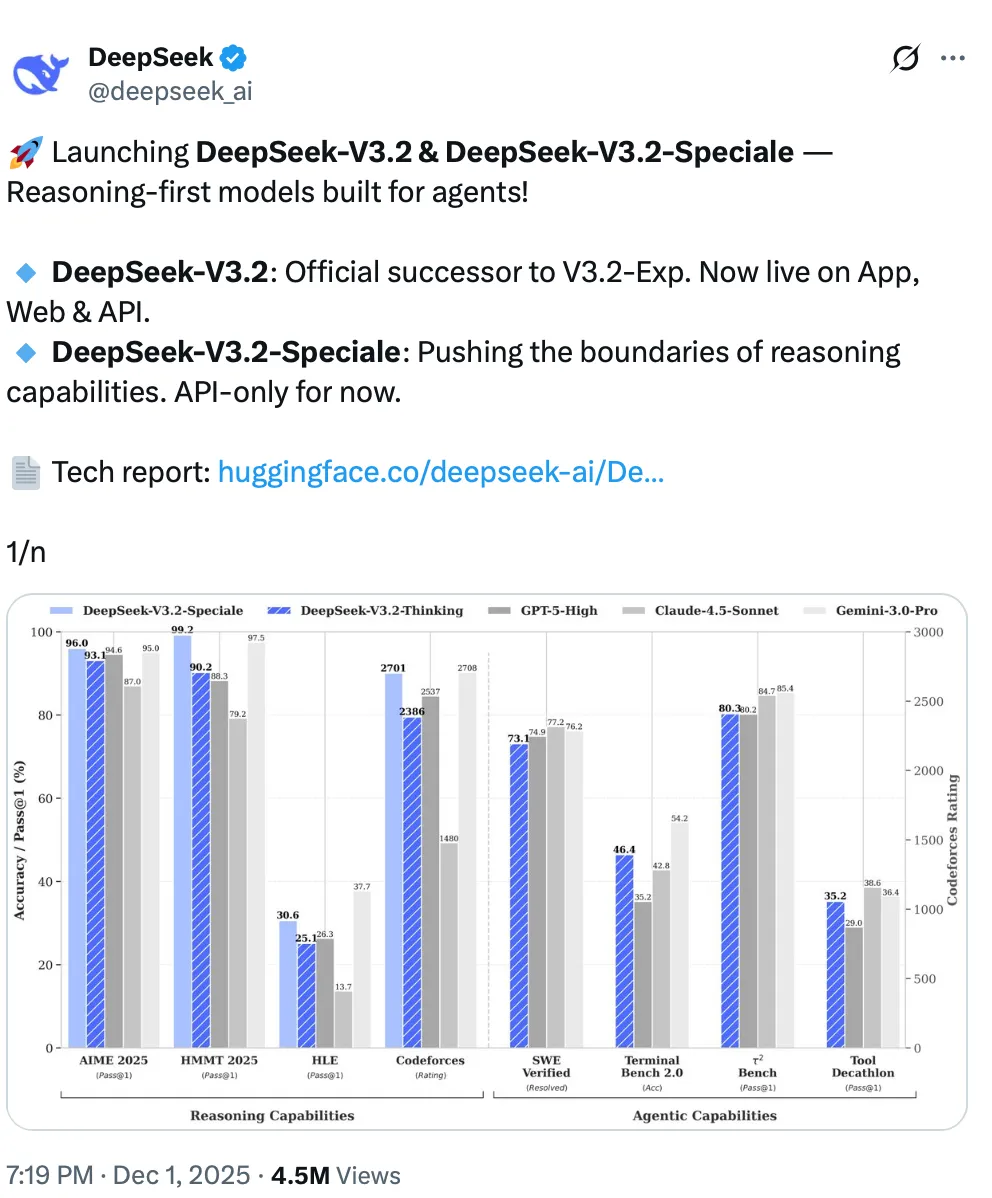
The results speak for themselves. DeepSeek-V3.2 achieves comparable performance to GPT-5 on reasoning benchmarks. The high-compute variant, DeepSeek-V3.2-Speciale, reaches parity with Gemini-3.0-Pro and earned gold-medal performance in IMO 2025, IOI 2025, and ICPC World Finals 2025.
The endgame: who wins?
This isn’t just a technical competition. It’s a bet on which future materializes.
If Scaling keeps working: If the Scaling Hypothesis continues to deliver, and compute concentration isn’t disrupted by regulation or technical workarounds, Silicon Valley’s approach is correct. The scarce fuel for the road to higher intelligence is almost entirely in their hands. China, capped by physical compute limits, may find itself locked into “localized applications + vertical niches”—useful, but not leading.
If Scaling hits a wall: If LLMs ultimately plateau at “extremely powerful pattern recognition + engineering-grade reasoning tools” rather than AGI, the bubble will burst at the most aggressive end. Over the past few years, much of U.S. capital markets priced assets assuming “new industrial revolution + AGI endgame dividends.” If that story doesn’t deliver, valuation corrections, debt burdens, and asset repricing become inevitable.
In a Scaling-hits-the-wall scenario, the DeepSeek-style approach shows remarkable resilience. From the start, this narrative never assumed AGI as a near-term premise. Instead, it bet on efficiency gains in concrete industries—manufacturing, healthcare, government services.
Here’s the irony: U.S. chip restrictions, while limiting China’s compute ceiling, also accidentally capped downside risk. This costly “protection” kept Chinese AI’s leverage and valuations from reaching dangerous extremes. When assets globally go on sale, the pragmatic side may have more room to acquire technology and talent at a discount.
The real question
Who wins won’t be decided by any single year’s benchmark rankings. It comes down to two core tests:
Technically: Can LLM Scaling, as the dominant paradigm, support something approaching AGI within a reasonable timeframe?
Economically: Who can convert “model capability” into “real productivity” faster and more sustainably?
If the answer is the former, Silicon Valley wins on ceiling. If the answer is the latter, the pragmatists may win on staying power.
Neither outcome is certain. But DeepSeek-V3.2—by being unusually honest about where things stand—has given us a clearer view of the fork in the road.