Gemini 3.0 dropped yesterday and the whole AI world lit up. Benchmarks, demo clips, and hot takes flooded everyone’s feed. OpenAI and Sam Altman have been at the center of this drama for the past couple of years, so another round of comparison and snark was inevitable. While people were still scrolling through Gemini charts, Altman quietly played his next card: GPT-5.1 Codex-Max. It doesn’t feel like a routine point release; it feels like a direct, high-signal answer to Gemini 3.0.
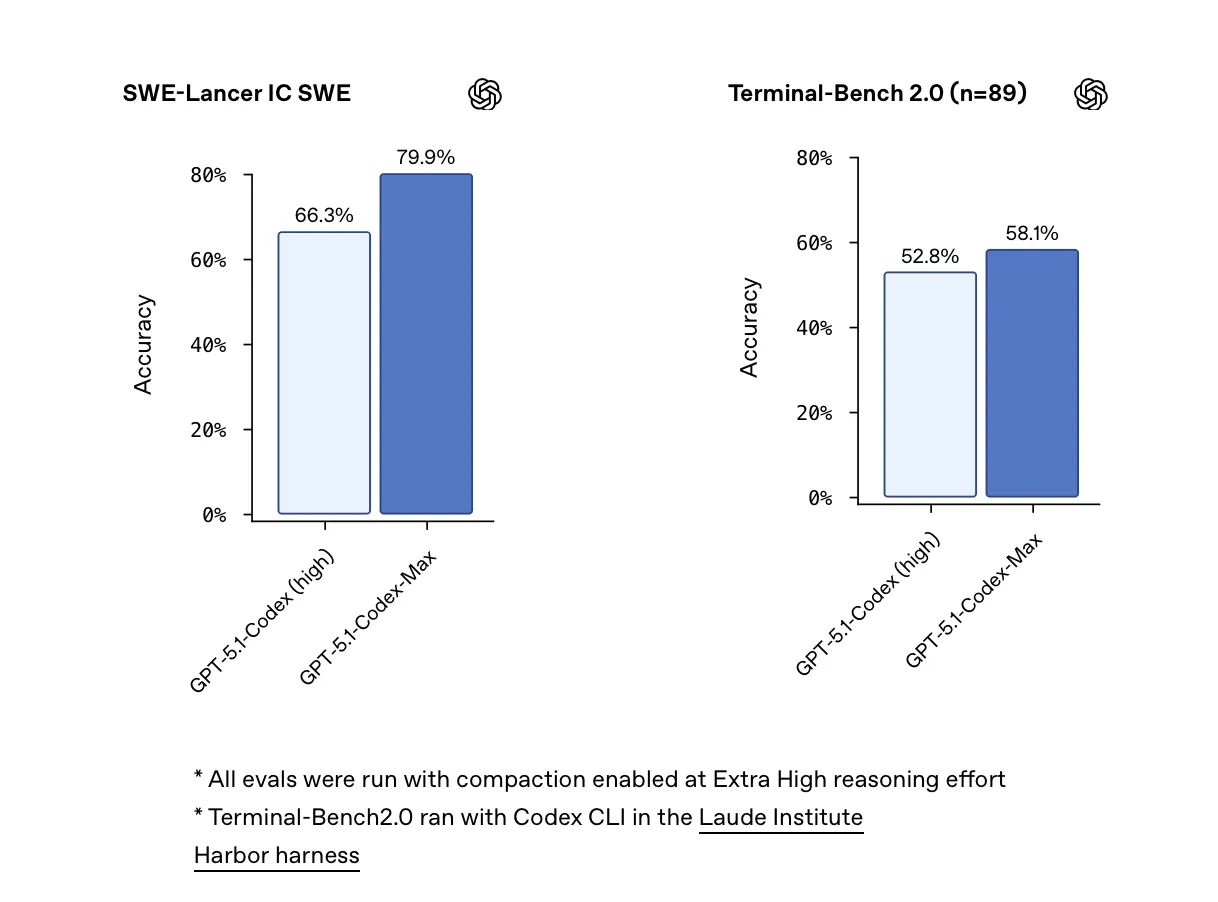
The first thing people started screenshotting was not a demo, but a number. Codex-Max posts new state-of-the-art results on SWE-bench, beating the previous GPT-5.1 Codex and edging out Gemini 3.0. No benchmark captures “real life” perfectly, and SWE-bench is still just one synthetic test bed. But numbers like this do reveal priority: OpenAI is clearly treating “write and ship code” as a first-class workload, not just talking about abstract, general intelligence in press-friendly language.
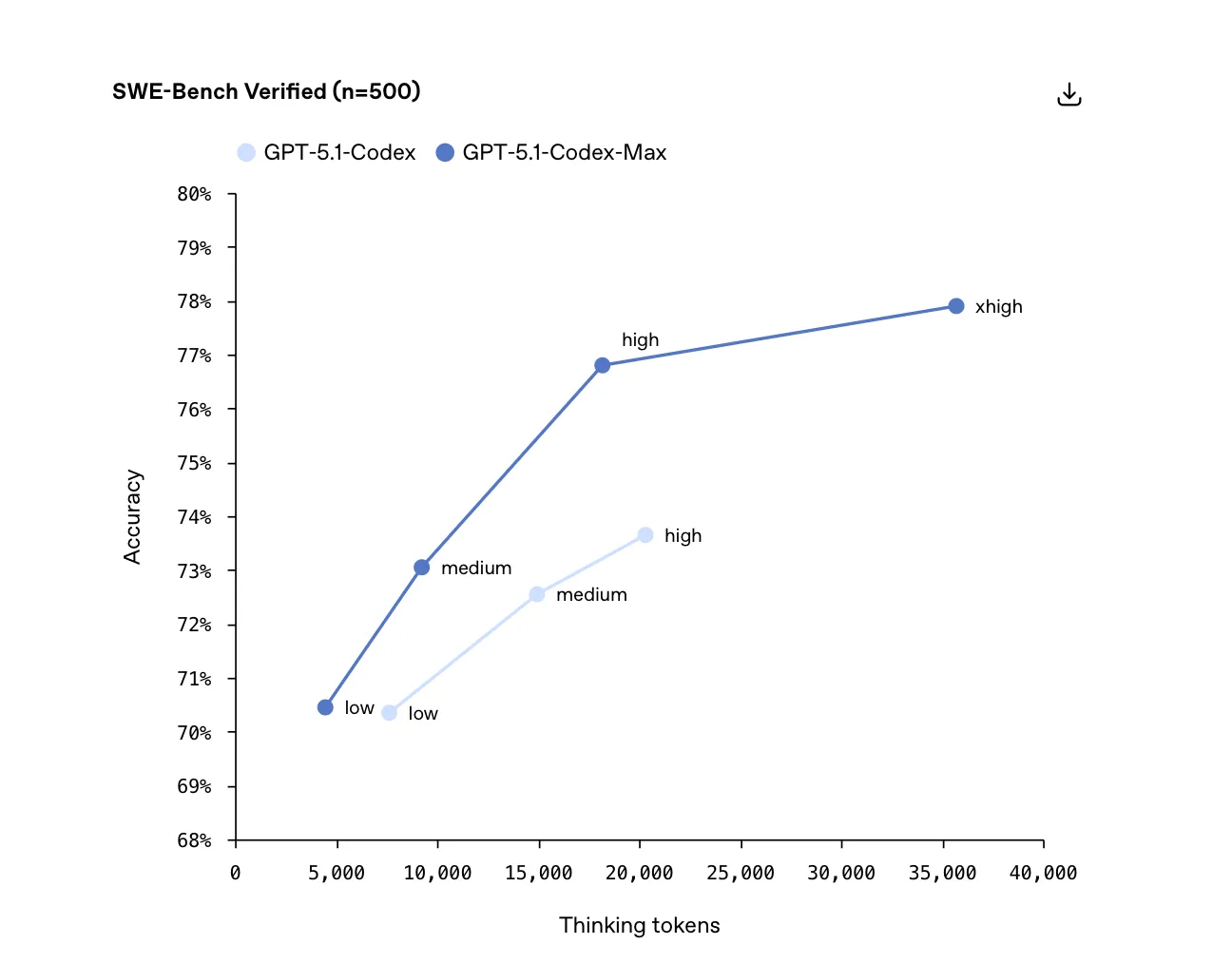
More interesting than the scoreline is the cost curve. According to OpenAI’s own numbers, Codex-Max manages to push capability without pushing the bill up; the medium tier even gets roughly 30% cheaper. In a year when GPU supply, inference cost, and “who can even afford to train the next model” dominate every conference hallway conversation, that pricing chart is as much a message to the market as it is a product detail. On top of that, OpenAI added a new xhigh tier: it thinks longer, digs deeper, and happily burns through tokens. This is not the tier you pick for casual chat; it is the lever you pull for a small set of high-stakes jobs where extra brainpower is worth the burn.
Codex-Max did not show up alone. Alongside it, OpenAI rolled out GPT-5.1 Pro for paying Pro users, and many early testers describe it in similar terms: it no longer feels like a chatbot sitting across from you; it feels like a colleague sitting next to you. Writing is sharper, reasoning is more compact, and the overall structure of answers is cleaner. When you hand it long, messy problems, the way it unpacks them feels less like autocomplete and more like talking to someone who has done this kind of work before.
You can see this in how people talk about day-to-day use:
- It behaves more like a real domain expert than a “friendly companion” app.
- Its answers have stronger structure and clearer trade-offs instead of hedged, sprawling paragraphs.
- On research, planning, and strategy questions—the kind of prompts that actually influence decisions—it is more willing to propose concrete paths forward.
- In many testers’ words, it feels “unreasonably smart” in a way that is starting to blur the line between tool and teammate.
If you zoom the timeline out a bit, the pattern is obvious. One track is pure competition: respond to Gemini 3.0 directly on scores, latency, and price. The other track is quieter but more important: reassure the people who now run their days on these systems—developers who ship code with AI pair programming, analysts who live inside long-form reports, and teams who lean on models for real decisions. GPT-5.1 Codex-Max is a benchmark headline, but it is also a promise to that group that OpenAI is still trying to build a dependable colleague, not just a flashy demo for the next launch event.