OpenAI has released GPT‑5.2-Codex, its latest agentic coding model tuned for complex, real-world software engineering and defensive cybersecurity. The overall update feels deliberately restrained: OpenAI claims state-of-the-art results on SWE‑Bench Pro and Terminal‑Bench 2.0, but the announcement reads more like a careful, incremental push than a “new era overnight” kind of moment.
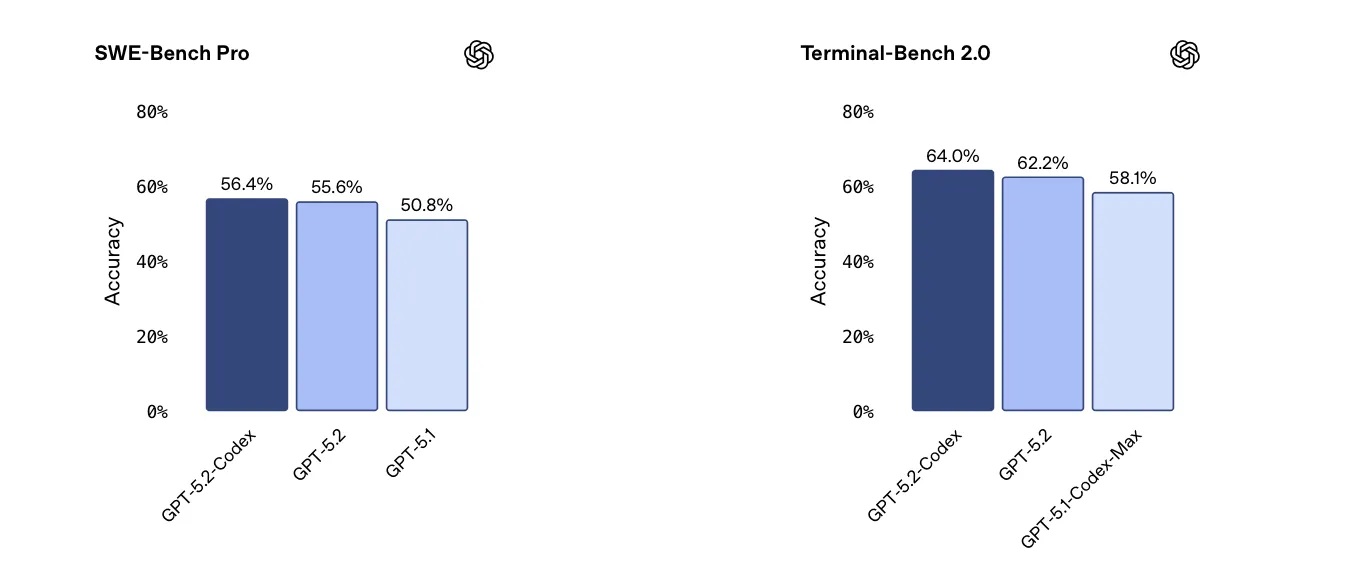
What stands out isn’t a single flashy feature, but the practical areas the model is being optimized for: long-horizon work via context compaction, more reliable tool use, better performance on large code changes like refactors and migrations, and stronger behavior in native Windows environments. In OpenAI’s framing, these aren’t nice-to-haves—they’re the difference between a model that can impress in a demo and one that can keep a large repository “in its head” long enough to actually ship changes.
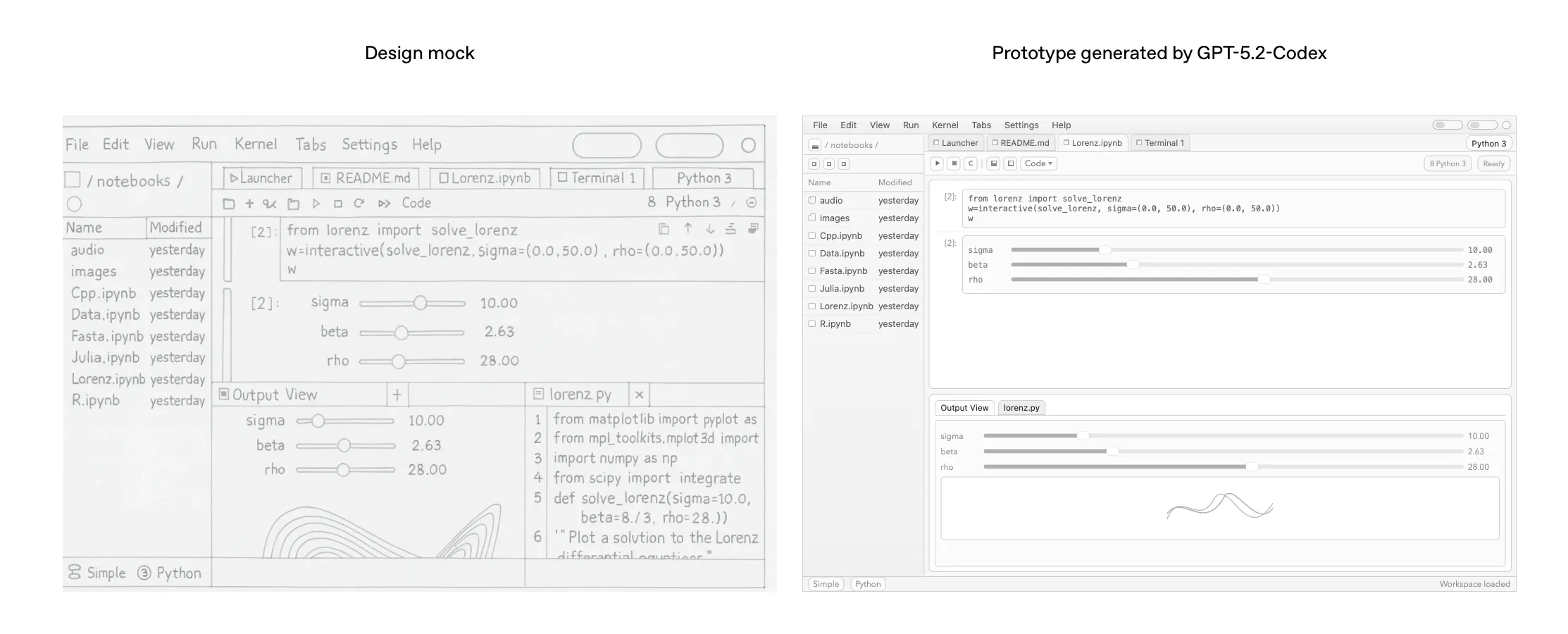
On the vision side, OpenAI highlights stronger ability to interpret screenshots, technical diagrams, charts, and UI surfaces during coding sessions, plus a faster path from design mocks to functional prototypes. That’s genuinely useful for front-end work, but it’s worth keeping expectations grounded: this feels less like the model suddenly gained “taste,” and more like it got better at faithfully executing what you provide. If the mock is detailed and consistent, it can translate that intent into code with fewer misses. If the input is vague or messy, it will still produce something that reflects that vagueness—just more accurately.
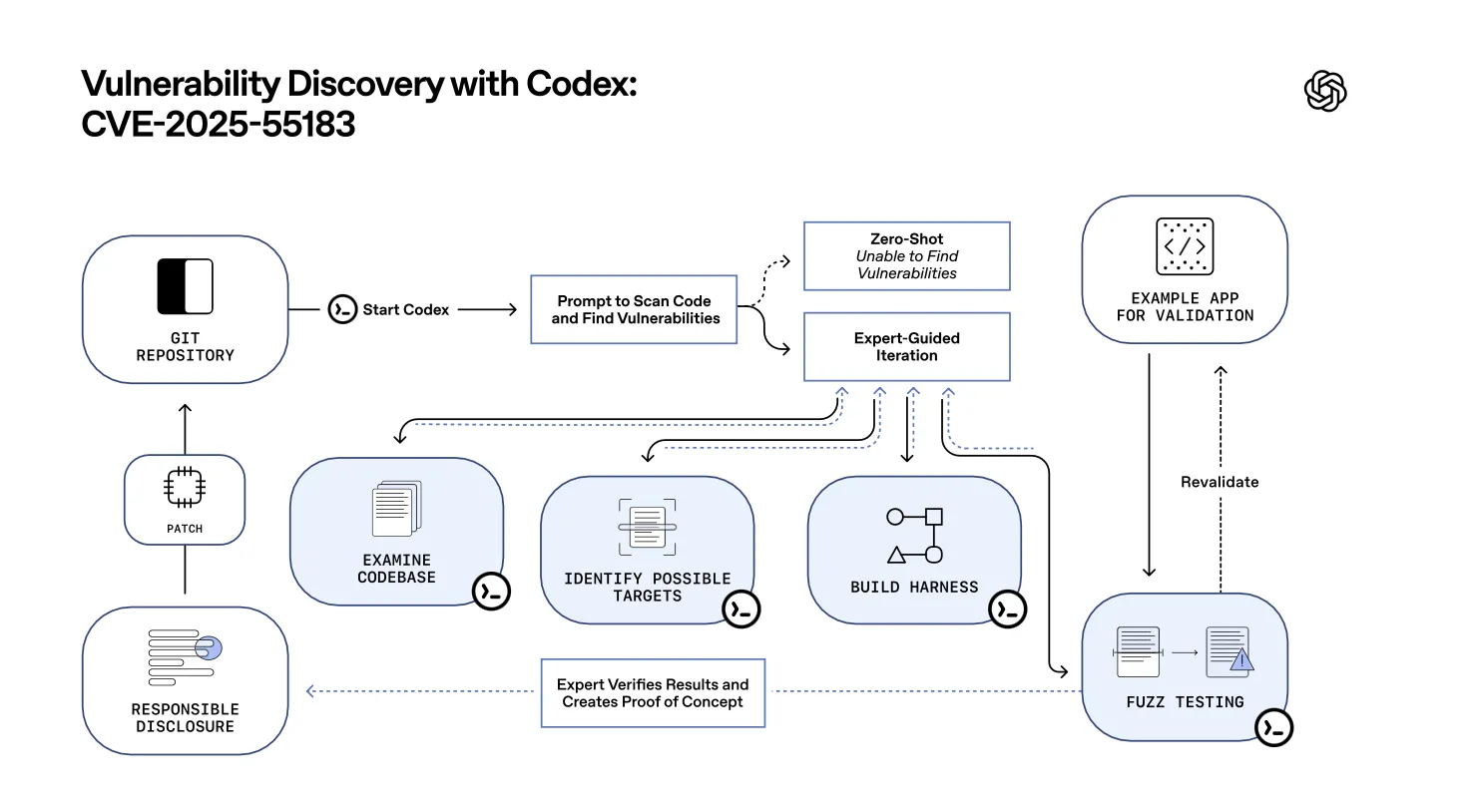
A big chunk of the release focuses on defensive cybersecurity, and it’s not just generic positioning. OpenAI says GPT‑5.2-Codex has its strongest cybersecurity capabilities so far, while noting it does not reach a “High” level under its Preparedness Framework—one reason the rollout and safeguards are framed as deliberately cautious. OpenAI points to a recent React disclosure involving React Server Components, where a security researcher (Andrew MacPherson, Privy) used GPT‑5.1-Codex-Max alongside Codex CLI and other coding agents while reproducing a separate critical issue known as React2Shell (CVE-2025-55182). In the process, he uncovered previously unknown vulnerabilities that could lead to source code exposure and worked with the React team to disclose them responsibly.
The part that matters operationally is what didn’t work. OpenAI’s account makes it clear that “zero-shot, fully automatic vulnerability fixing” isn’t the reality here. The effective path was expert-led iteration: setting up a local test environment, reasoning about attack surfaces, building a minimal harness, and using fuzzing to probe the system with malformed inputs—then validating, confirming, and following responsible disclosure. In other words, Codex acts like an accelerator that compresses the repetitive parts of the workflow, not a replacement for the judgment and proof required to ship a security fix.
That emphasis also clarifies OpenAI’s trade-offs. This release doesn’t spend much time promising “dramatically faster generations” or “magically better UI aesthetics.” Instead, it doubles down on the parts of professional work that are easiest to verify and hardest to fake: back-end logic, debugging, reviews, and the ability to keep making progress through failed attempts without losing the plot.
For everyday “vibe coding” users, that can land in two very different ways. If your biggest pain is UI aesthetics, raw speed, or token burn, GPT‑5.2-Codex may not feel like it’s prioritizing your wishlist. If what you want is fewer dead ends when you’re debugging, reviewing, or pushing a risky refactor through a real codebase, the direction is clearer—and more defensible.
In my own day-to-day use, the major coding models are starting to feel like three distinct “debugging philosophies.” Gemini can be powerful but often comes with a higher audit cost when details matter. Claude is the safest default when you’re unsure what to pick. Codex tends to be slower and more expensive on tokens, but it’s often more reliable for review/debug work and for back-end changes where small mistakes become expensive later. On the UI side, it still benefits heavily from explicit references and existing styles—but when you give it a clear target, it’s usually good at matching it.
OpenAI announcement: https://openai.com/index/introducing-gpt-5-2-codex/