Codex is already a top-tier model. But if you compare “Skills hype” between Codex and Claude, I think Codex lagged for two simple reasons:
- It’s slower. The accuracy is good, but in my day-to-day use it can be several times slower than Claude.
- It didn’t have multi-agents.
These two issues are independent, but they’re also connected: fix either one, and your end-to-end throughput improves. Speed probably won’t change the way people hope—OpenAI’s direction is clearly “reasoning first.” So I was much more interested in the second point. And finally, after Codex 0.88, it shipped experimental subagents (multi-agents).
Because it’s still experimental, there isn’t much official documentation yet. I pieced things together from community notes. Huge thanks to am.will for writing “Codex Subagents: A Deep Dive”—it’s the most readable explanation I’ve seen.

Turning on Multi-Agents (what I did on macOS)
First, make sure you’re on Codex >= 0.88.
Then in the UI, enable the experimental option:
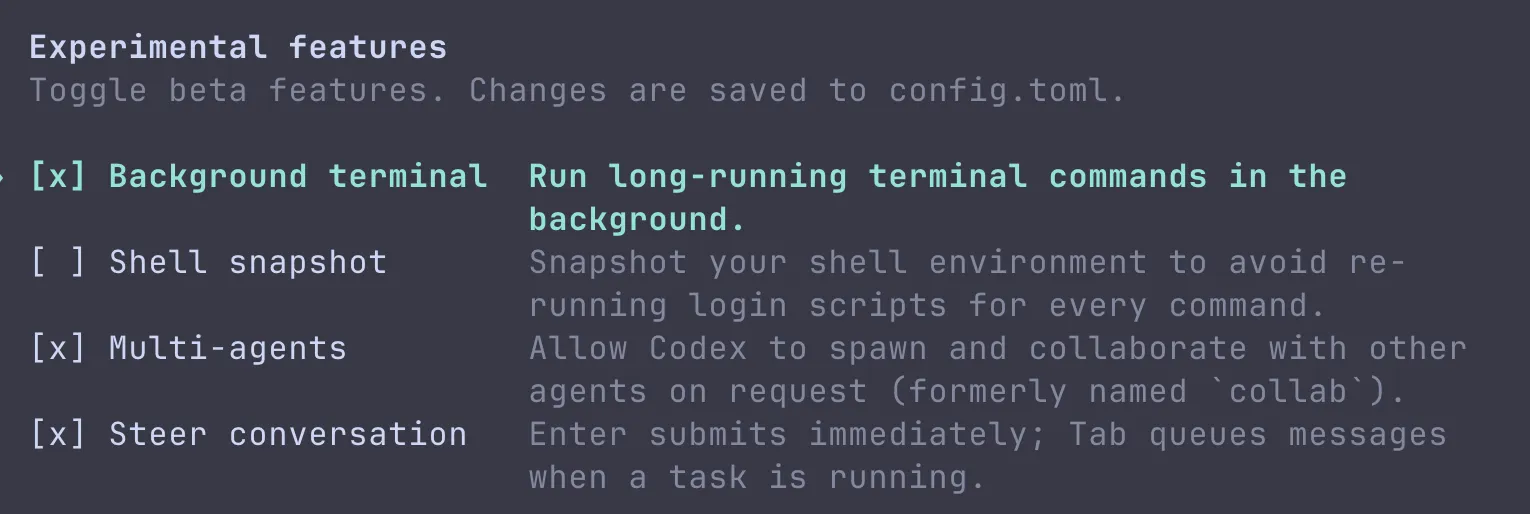
Finally, confirm your local config includes collab = true:
[features]
collab = true
I’m on macOS. I can’t give solid advice for Windows (sorry). I didn’t test Linux, but I suspect it’s the same.
One more thing: there isn’t a /spawn command you type manually. From what I’ve seen, there are two ways subagents appear:
- Codex decides to launch them automatically.
- You explicitly tell it to use multi-agents for a task.
If you’re curious what the system prompts look like, OpenAI keeps templates in the Codex repo. This path is a fun rabbit hole:
https://github.com/openai/codex/blob/main/codex-rs/core/templates/
The workload: my “lots of images” pipeline
My real need is boring but heavy: a pile of images that need to be processed into something usable.
The exact steps vary, but the backbone is always the same:
- convert image formats
- read/recognize what’s in the images
- label/tag + categorize
- output a final summary
The number of images isn’t stable. Sometimes it’s 60. Sometimes it’s 100+. In the past, I’d throw a single agent at it (usually high or xhigh) and let it grind.
I already optimized the process: stitch images into grids, write helper scripts, reduce repeated work. It helped, but it didn’t solve the core issue: it was still slow, and the accuracy was not perfectly stable. My guess is long context + attention drift: some images end up mismatched.
Even at ~60 images, high could take 30+ minutes. 100+ images often pushed it to an hour. On xhigh, I’ve seen it hit two hours.

What Multi-Agents changed: Orchestrator + Workers
am.will describes two roles:
- Orchestrator: the manager that plans and coordinates
- Workers: do the actual work
In practice, that maps nicely to my pipeline. I don’t need one brilliant agent to hold everything in its head. I need parallel workers and a clean merge step.
So I asked the Orchestrator to:
- spawn workers based on the image count (roughly 20 images per worker)
- have workers do the per-image work in parallel
- add one worker to merge outputs and check for stitching/mismatch errors
- avoid re-recognizing images during the merge (otherwise the earlier work is wasted)
This kind of workflow is also where Skills help: the more repeatable you make the boundaries, the less “drift” you get from orchestration.
My run: 131 images, ~36 minutes, and higher accuracy
I tested it on 131 images.
Codex spawned a bunch of workers, checked status as they ran, and then merged the results. It felt like the system was finally doing what I wanted: take a big pile of parallelizable work and actually parallelize it.
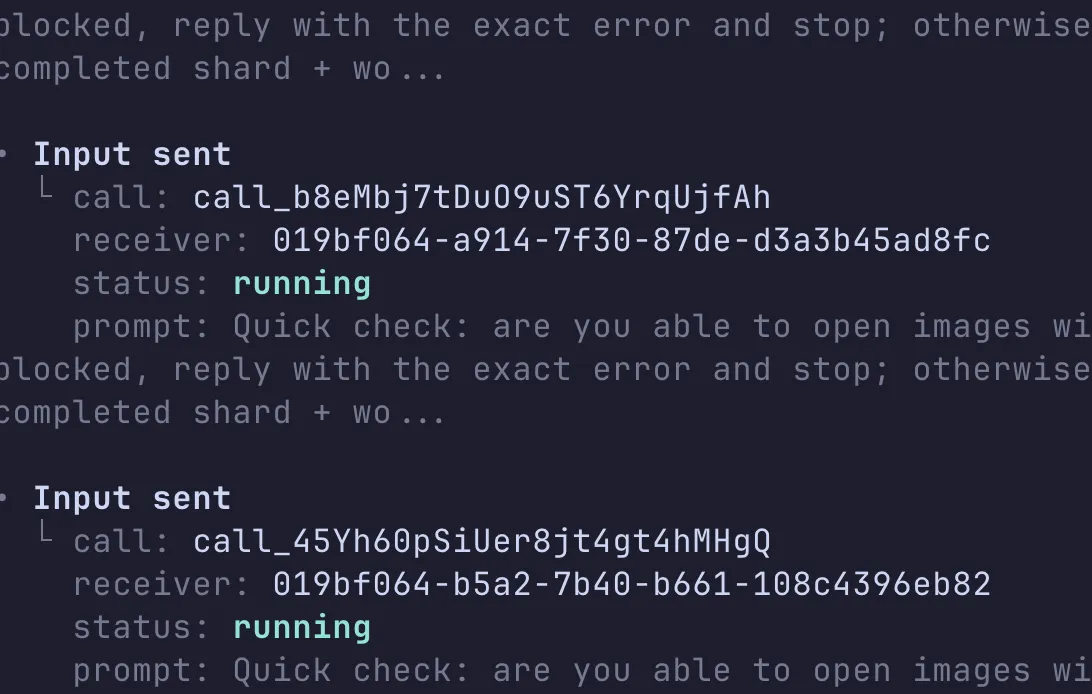
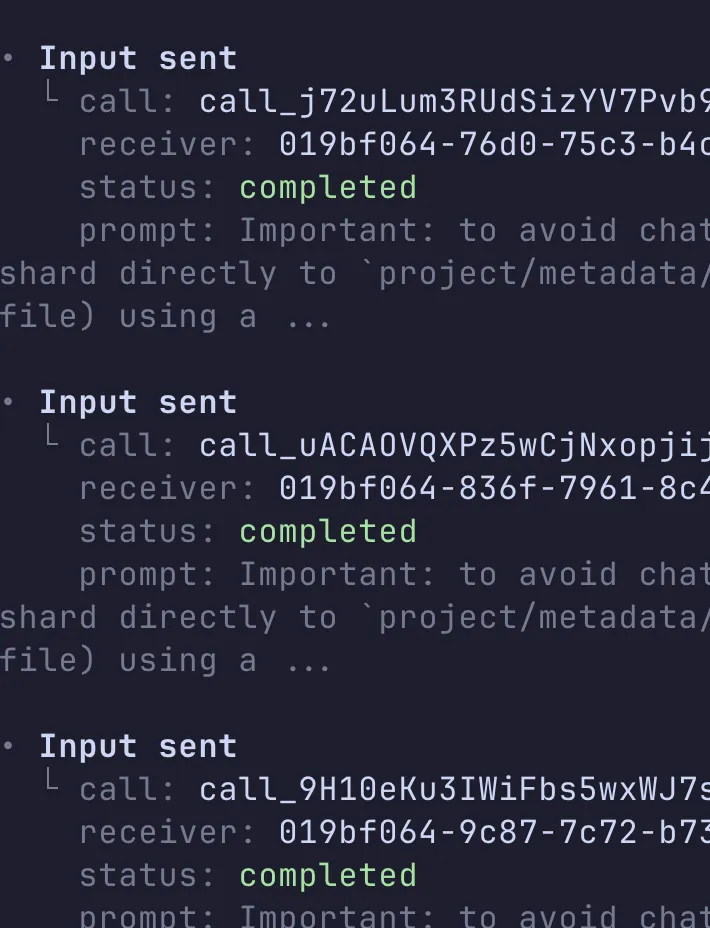
Because this was a real run, one of my Python scripts had a bug. Codex fixed it during the process, which cost me about 6 extra minutes. Even with that, the total runtime landed at ~36 minutes.
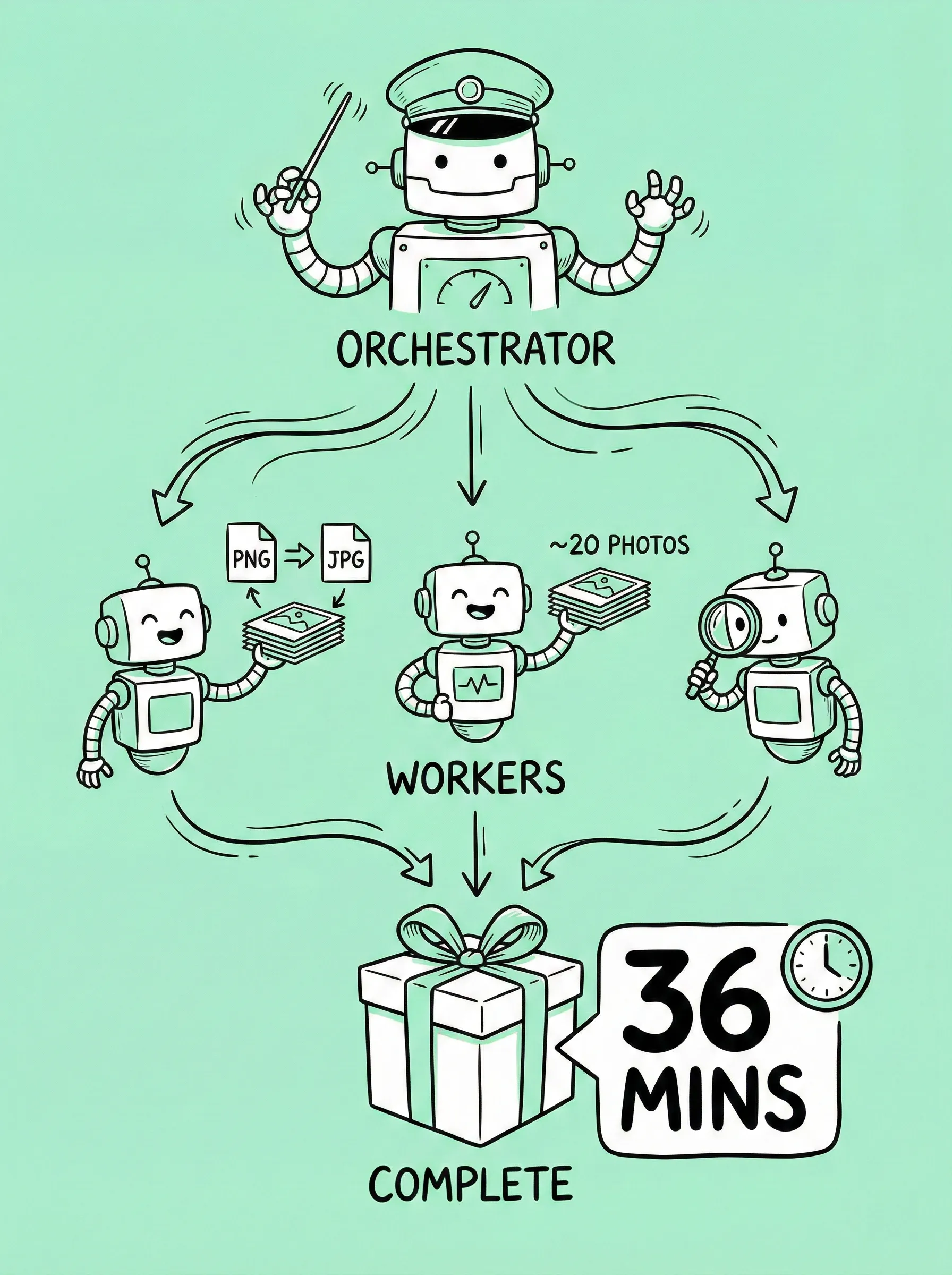
I manually checked the outputs. Accuracy was basically perfect. Only one image needed a subjective human call; everything else was correct.
If I did this with a single agent, I’d expect 1–2 hours and ~10 images needing correction. Multi-agents didn’t just make it faster—it made the result cleaner.
Token burn felt similar, maybe even slightly lower. I used xhigh. About 30 minutes cost me under 2% (I’m on Pro). I can’t confirm whether workers also ran at xhigh—it didn’t feel that slow, so I suspect they didn’t.
When multi-agents are not worth it (yet)
This is still experimental. The Orchestrator’s “prompt engineering” doesn’t feel polished yet.
am.will put it bluntly:
Codex can be steerable to a fault. Sometimes you really need hyper-specific prompting to get the desired result. My recommendation: create a skill for any workflow involving subagents so you can generate highly repeatable outcomes.
Avoid assuming the subagent is returning useful information. Also avoid assuming the Orc is providing correct context to your subagents.
That matches my experience. For now, you should assume:
- You need to be explicit.
- You need validation.
- Skills make multi-agent workflows much more reliable.
Also: if you only have 10 images, swarming probably isn’t worth it. Like everything else, it’s a trade-off. But for my “60–100+ images” days, multi-agents are the first thing that made this workflow feel truly scalable.